近日,地球科学学院副教授罗水亮在《特种油气藏》发表题为“基于改进Stacking算法的碳酸盐岩储层测井岩性识别方法与应用”的研究论文(图1)。罗水亮为第一作者,长江大学为第一完成单位。

图1.文章首页截图
针对川中地区碳酸盐岩储层传统岩性识别方法精度低、模型泛化能力弱的问题,提出一种基于改进Stacking算法的测井岩性识别方法。该方法融合多种机器学习模型的优势,优化特征加权策略,可提高对测井曲线关键信息的提取能力,同时增强对复杂岩性的识别准确性和稳定性。相比传统方法,该模型能够更有效地捕捉测井数据的非线性关系,并降低不同岩性类别间的预测混淆度。据岩心资料和薄片鉴定结果可知,研究区主要发育泥质灰岩、泥质云岩、石灰岩、云质灰岩、灰质云岩、白云岩等6种碳酸盐岩类型(图2),其他岩性样本较少,不作为研究对象。
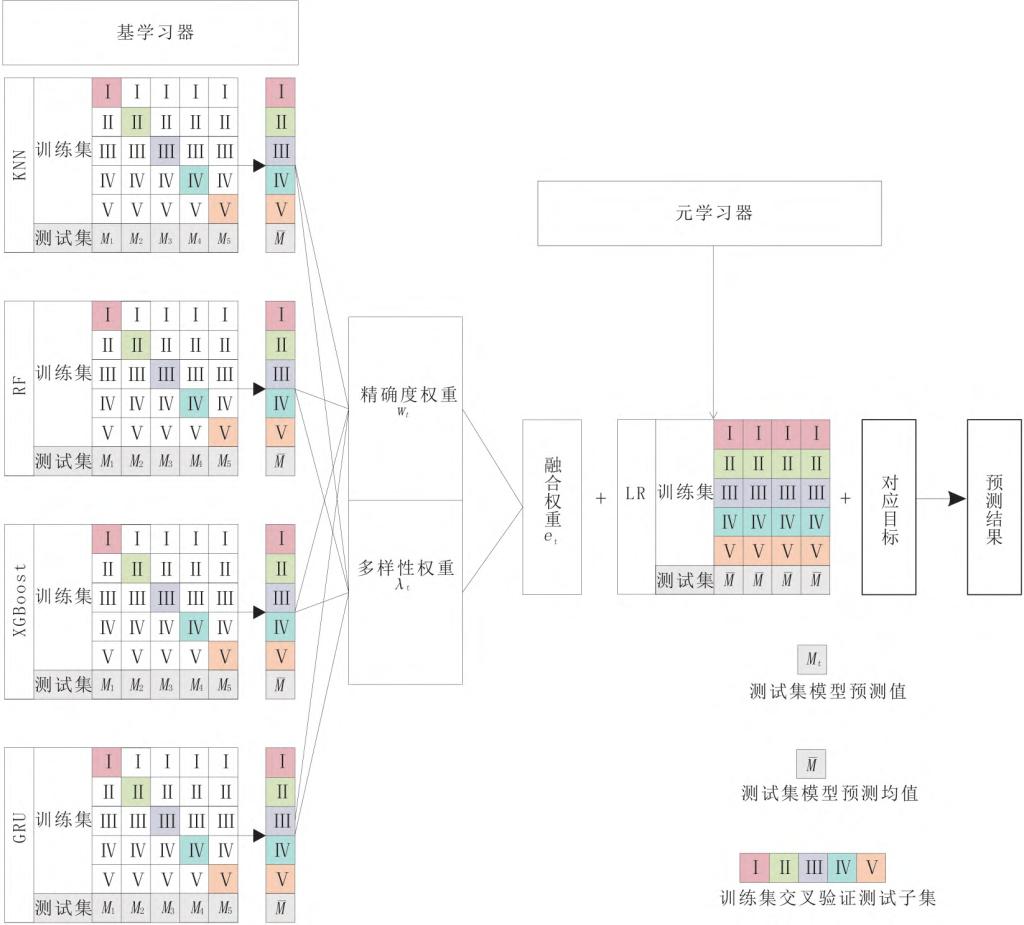
图2.改进Stacking模型示意图
研究结果表明,KNN、GRU、RF、XGBoost、传统Stacking和改进Stacking算法对碳酸盐岩储层岩性的识别准确率分别为73%、85%、87%、88%、90%、96%;改进Stacking算法的集成学习模型识别精度最高,较单一模型平均提高了12个百分点,比传统Stacking算法提高了6个百分点。由图3可知,过渡岩性中泥质岩性的识别精度高于云灰岩和灰云岩,泥质对碳酸盐岩测井曲线特征响应比较明显,表现为高GR,因此,在过渡岩性中泥质岩性识别精度较高。石灰岩和白云岩及其过渡岩性在岩石化学分析实验中主要表现为方解石和白云石矿物含量的差异,其测井响应特征相似,因此,过渡岩性识别精度较低。高纯度矿物岩性石灰岩和白云岩识别精度较高。改进Stacking集成模型集成学习算法相对于单一模型和传统集成学习模型识别正确的比例最高,分类效果也更加理想。
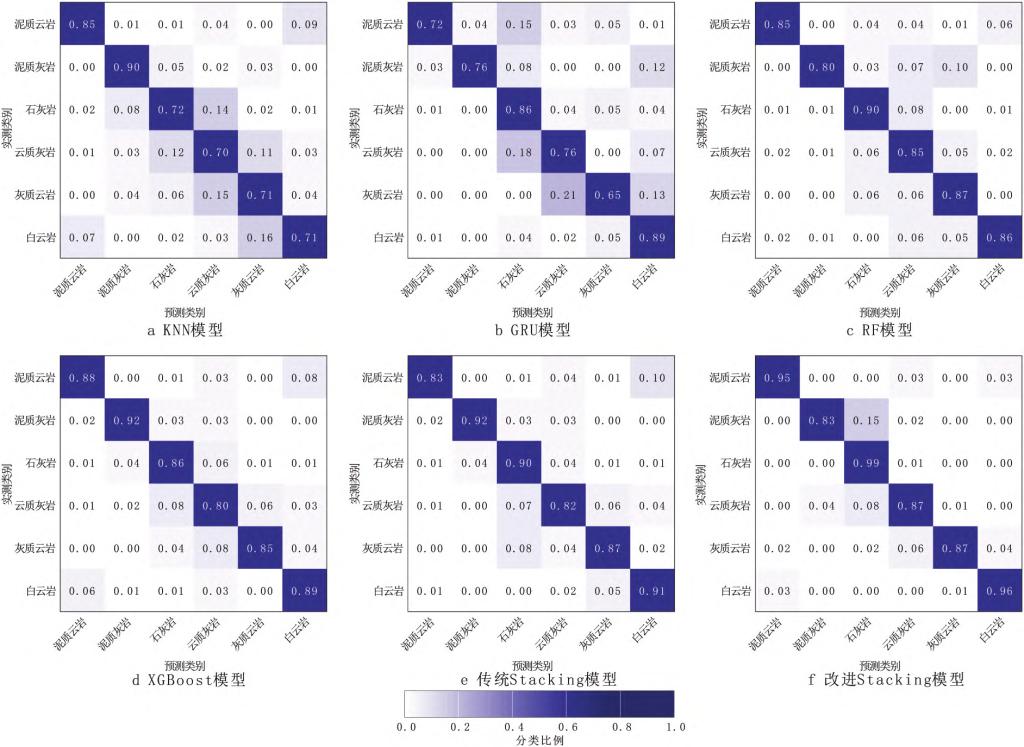
图3.不同碳酸盐岩储层岩性识别模型的混淆矩阵
在计算效率方面,改进Stacking模型通过优化特征加权策略,使得训练时间减少了15%,在保证高精度的同时,大幅提升了计算效率。该算法通过选择性增强特征权重,实现了样本精确度和多样性的平衡,由于改进模型有效地提取了测井资料与岩性特征的非线性关系,从而消除了传统机器学习算法过拟合问题和泛化能力弱的弊端,并且解决了复杂储层过渡岩性难以分类的问题,进一步提高了模型的识别准确性。改进Stacking算法复杂碳酸盐岩岩性识别模型利用多模型集成融合深度序列特征在研究区取得了较好的预测效果,对四川盆地川中地区碳酸盐岩储层预测具有一定的指导作用。
论文信息:罗水亮,漆影强,唐松,等.基于改进Stacking算法的碳酸盐岩储层测井岩性识别方法与应用[J].特种油气藏,2025,32( 4) : 58-67.
参考文献:
1.赵文智,沈安江,乔占峰,等.中国碳酸盐岩沉积储层理论进展与海相大油气田发现[J]中国石油勘探,2022,27(4):1-15.
2.成大伟,袁选俊,周川闽,等.测井岩性识别方法及应用——以鄂尔多斯盆地中西部长7油层组为例[J].中国石油勘探,2016,21( 5) : 117-126.

